Integrating dbt and ClickHouse
dbt (data build tool) enables analytics engineers to transform data in their warehouses by simply writing select statements. dbt handles materializing these select statements into objects in the database in the form of tables and views - performing the T of Extract Load and Transform (ELT). Users can create a model defined by a SELECT statement.
Within dbt, these models can be cross-referenced and layered to allow the construction of higher-level concepts. The boilerplate SQL required to connect models is automatically generated. Furthermore, dbt identifies dependencies between models and ensures they are created in the appropriate order using a directed acyclic graph (DAG).
Dbt is compatible with ClickHouse through a ClickHouse-supported plugin. We describe the process for connecting ClickHouse with a simple example based on a publicly available IMDB dataset. We additionally highlight some of the limitations of the current connector.
Concepts
dbt introduces the concept of a model. This is defined as a SQL statement, potentially joining many tables. A model can be “materialized” in a number of ways. A materialization represents a build strategy for the model’s select query. The code behind a materialization is boilerplate SQL that wraps your SELECT query in a statement in order to create a new or update an existing relation.
dbt provides 4 types of materialization:
- view (default): The model is built as a view in the database.
- table: The model is built as a table in the database.
- ephemeral: The model is not directly built in the database but is instead pulled into dependent models as common table expressions.
- incremental: The model is initially materialized as a table, and in subsequent runs, dbt inserts new rows and updates changed rows in the table.
Additional syntax and clauses define how these models should be updated if their underlying data changes. dbt generally recommends starting with the view materialization until performance becomes a concern. The table materialization provides a query time performance improvement by capturing the results of the model’s query as a table at the expense of increased storage. The incremental approach builds on this further to allow subsequent updates to the underlying data to be captured in the target table.
The current plugin for ClickHouse supports the view, table,, ephemeral and incremental materializations. The plugin also supports dbt snapshots and seeds which we explore in this guide.
For the following guides, we assume you have a ClickHouse instance available.
Setup of dbt and the ClickHouse plugin
dbt
We assume the use of the dbt CLI for the following examples. Users may also wish to consider dbt Cloud, which offers a web-based Integrated Development Environment (IDE) allowing users to edit and run projects.
dbt offers a number of options for CLI installation. Follow the instructions described here. At this stage install dbt-core only. We recommend the use of pip.
pip install dbt-core
Important: The following is tested under python 3.9.
ClickHouse plugin
Install the dbt ClickHouse plugin:
pip install dbt-clickhouse
Prepare ClickHouse
dbt excels when modeling highly relational data. For the purposes of example, we provide a small IMDB dataset with the following relational schema. This dataset originates from the relational dataset repository. This is trivial relative to common schemas used with dbt but represents a manageable sample:
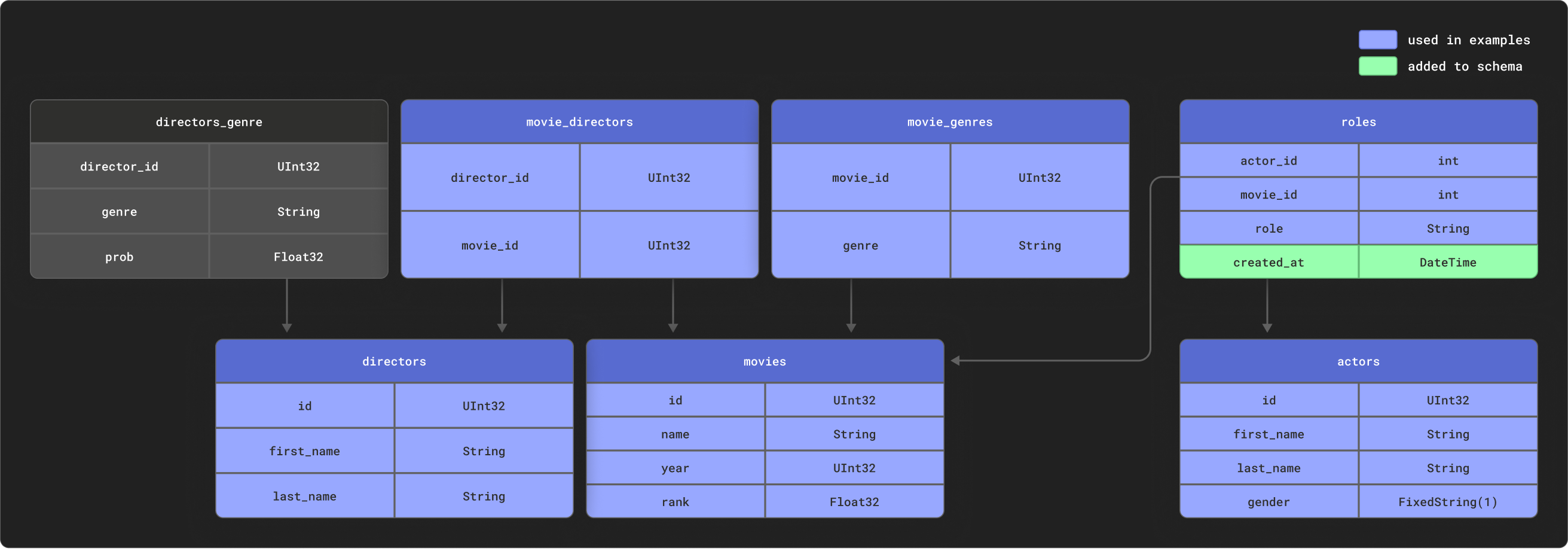
We use a subset of these tables as shown.
Create the following tables:
CREATE DATABASE imdb;
CREATE TABLE imdb.actors
(
id UInt32,
first_name String,
last_name String,
gender FixedString(1)
) ENGINE = MergeTree ORDER BY (id, first_name, last_name, gender);
CREATE TABLE imdb.directors
(
id UInt32,
first_name String,
last_name String
) ENGINE = MergeTree ORDER BY (id, first_name, last_name);
CREATE TABLE imdb.genres
(
movie_id UInt32,
genre String
) ENGINE = MergeTree ORDER BY (movie_id, genre);
CREATE TABLE imdb.movie_directors
(
director_id UInt32,
movie_id UInt64
) ENGINE = MergeTree ORDER BY (director_id, movie_id);
CREATE TABLE imdb.movies
(
id UInt32,
name String,
year UInt32,
rank Float32 DEFAULT 0
) ENGINE = MergeTree ORDER BY (id, name, year);
CREATE TABLE imdb.roles
(
actor_id UInt32,
movie_id UInt32,
role String,
created_at DateTime DEFAULT now()
) ENGINE = MergeTree ORDER BY (actor_id, movie_id);
The column created_at for the table roles, which defaults to a value of now(). We use this later to identify incremental updates to our models - see Incremental Models.
We use the s3 function to read the source data from public endpoints to insert data. Run the following commands to populate the tables:
INSERT INTO imdb.actors
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_actors.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.directors
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_directors.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.genres
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_movies_genres.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.movie_directors
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_movies_directors.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.movies
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_movies.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.roles(actor_id, movie_id, role)
SELECT actor_id, movie_id, role
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_roles.tsv.gz',
'TSVWithNames');
The execution of these may vary depending on your bandwidth, but each should only take a few seconds to complete. Execute the following query to compute a summary of each actor, ordered by the most movie appearances, and to confirm the data was loaded successfully:
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as unique_genres,
uniqExact(director_name) as uniq_directors,
max(created_at) as updated_at
FROM (
SELECT imdb.actors.id as id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) as actor_name,
imdb.movies.id as movie_id,
imdb.movies.rank as rank,
genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) as director_name,
created_at
FROM imdb.actors
JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT OUTER JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT OUTER JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
ORDER BY num_movies DESC
LIMIT 5;
The response should look like:
+------+------------+----------+------------------+-------------+--------------+-------------------+
|id |name |num_movies|avg_rank |unique_genres|uniq_directors|updated_at |
+------+------------+----------+------------------+-------------+--------------+-------------------+
|45332 |Mel Blanc |832 |6.175853582979779 |18 |84 |2022-04-26 14:01:45|
|621468|Bess Flowers|659 |5.57727638854796 |19 |293 |2022-04-26 14:01:46|
|372839|Lee Phelps |527 |5.032976449684617 |18 |261 |2022-04-26 14:01:46|
|283127|Tom London |525 |2.8721716524875673|17 |203 |2022-04-26 14:01:46|
|356804|Bud Osborne |515 |2.0389507108727773|15 |149 |2022-04-26 14:01:46|
+------+------------+----------+------------------+-------------+--------------+-------------------+
In the later guides, we will convert this query into a model - materializing it in ClickHouse as a dbt view and table.
Connecting to ClickHouse
Create a dbt project. In this case we name this after our imdb source. When prompted, select
clickhouseas the database source.clickhouse-user@clickhouse:~$ dbt init imdb
16:52:40 Running with dbt=1.1.0
Which database would you like to use?
[1] clickhouse
(Don't see the one you want? https://docs.getdbt.com/docs/available-adapters)
Enter a number: 1
16:53:21 No sample profile found for clickhouse.
16:53:21
Your new dbt project "imdb" was created!
For more information on how to configure the profiles.yml file,
please consult the dbt documentation here:
https://docs.getdbt.com/docs/configure-your-profilecdinto your project folder:cd imdbAt this point, you will need the text editor of your choice. In the examples below, we use the popular VSCode. Opening the IMDB directory, you should see a collection of yml and sql files:
Update your
dbt_project.ymlfile to specify our first model -actor_summaryand set profile toclickhouse_imdb.

We next need to provide dbt with the connection details for our ClickHouse instance. Add the following to your
~/.dbt/profiles.yml.clickhouse_imdb:
target: dev
outputs:
dev:
type: clickhouse
schema: imdb_dbt
host: localhost
port: 8123
user: default
password: ''
secure: FalseNote the need to modify the user and password. There are additional available settings documented here.
From the IMDB directory, execute the
dbt debugcommand to confirm whether dbt is able to connect to ClickHouse.clickhouse-user@clickhouse:~/imdb$ dbt debug
17:33:53 Running with dbt=1.1.0
dbt version: 1.1.0
python version: 3.10.1
python path: /home/dale/.pyenv/versions/3.10.1/bin/python3.10
os info: Linux-5.13.0-10039-tuxedo-x86_64-with-glibc2.31
Using profiles.yml file at /home/dale/.dbt/profiles.yml
Using dbt_project.yml file at /opt/dbt/imdb/dbt_project.yml
Configuration:
profiles.yml file [OK found and valid]
dbt_project.yml file [OK found and valid]
Required dependencies:
- git [OK found]
Connection:
host: localhost
port: 8123
user: default
schema: imdb_dbt
secure: False
verify: False
Connection test: [OK connection ok]
All checks passed!Confirm the response includes
Connection test: [OK connection ok]indicating a successful connection.
Creating a Simple View Materialization
When using the view materialization, a model is rebuilt as a view on each run, via a CREATE VIEW AS statement in ClickHouse. This doesn't require any additional storage of data but will be slower to query than table materializations.
From the
imdbfolder, delete the directorymodels/example:clickhouse-user@clickhouse:~/imdb$ rm -rf models/exampleCreate a new file in the
actorswithin themodelsfolder. Here we create files that each represent an actor model:clickhouse-user@clickhouse:~/imdb$ mkdir models/actorsCreate the files
schema.ymlandactor_summary.sqlin themodels/actorsfolder.clickhouse-user@clickhouse:~/imdb$ touch models/actors/actor_summary.sql
clickhouse-user@clickhouse:~/imdb$ touch models/actors/schema.ymlThe file
schema.ymldefines our tables. These will subsequently be available for use in macros. Editmodels/actors/schema.ymlto contain this content:version: 2
sources:
- name: imdb
tables:
- name: directors
- name: actors
- name: roles
- name: movies
- name: genres
- name: movie_directorsThe
actors_summary.sqldefines our actual model. Note in the config function we also request the model be materialized as a view in ClickHouse. Our tables are referenced from theschema.ymlfile via the functionsourcee.g.source('imdb', 'movies')refers to themoviestable in theimdbdatabase. Editmodels/actors/actors_summary.sqlto contain this content:{{ config(materialized='view') }}
with actor_summary as (
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as genres,
uniqExact(director_name) as directors,
max(created_at) as updated_at
FROM (
SELECT {{ source('imdb', 'actors') }}.id as id,
concat({{ source('imdb', 'actors') }}.first_name, ' ', {{ source('imdb', 'actors') }}.last_name) as actor_name,
{{ source('imdb', 'movies') }}.id as movie_id,
{{ source('imdb', 'movies') }}.rank as rank,
genre,
concat({{ source('imdb', 'directors') }}.first_name, ' ', {{ source('imdb', 'directors') }}.last_name) as director_name,
created_at
FROM {{ source('imdb', 'actors') }}
JOIN {{ source('imdb', 'roles') }} ON {{ source('imdb', 'roles') }}.actor_id = {{ source('imdb', 'actors') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movies') }} ON {{ source('imdb', 'movies') }}.id = {{ source('imdb', 'roles') }}.movie_id
LEFT OUTER JOIN {{ source('imdb', 'genres') }} ON {{ source('imdb', 'genres') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movie_directors') }} ON {{ source('imdb', 'movie_directors') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'directors') }} ON {{ source('imdb', 'directors') }}.id = {{ source('imdb', 'movie_directors') }}.director_id
)
GROUP BY id
)
select *
from actor_summaryNote how we include the column
updated_atin our final actor_summary. We use this later for incremental materializations.From the
imdbdirectory execute the commanddbt run.clickhouse-user@clickhouse:~/imdb$ dbt run
15:05:35 Running with dbt=1.1.0
15:05:35 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
15:05:35
15:05:36 Concurrency: 1 threads (target='dev')
15:05:36
15:05:36 1 of 1 START view model imdb_dbt.actor_summary.................................. [RUN]
15:05:37 1 of 1 OK created view model imdb_dbt.actor_summary............................. [OK in 1.00s]
15:05:37
15:05:37 Finished running 1 view model in 1.97s.
15:05:37
15:05:37 Completed successfully
15:05:37
15:05:37 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1dbt will represent the model as a view in ClickHouse as requested. We can now query this view directly. This view will have been created in the
imdb_dbtdatabase - this is determined by the schema parameter in the file~/.dbt/profiles.ymlunder theclickhouse_imdbprofile.SHOW DATABASES;+------------------+
|name |
+------------------+
|INFORMATION_SCHEMA|
|default |
|imdb |
|imdb_dbt | <---created by dbt!
|information_schema|
|system |
+------------------+Querying this view, we can replicate the results of our earlier query with a simpler syntax:
SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 5;+------+------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+------------+----------+------------------+------+---------+-------------------+
|45332 |Mel Blanc |832 |6.175853582979779 |18 |84 |2022-04-26 15:26:55|
|621468|Bess Flowers|659 |5.57727638854796 |19 |293 |2022-04-26 15:26:57|
|372839|Lee Phelps |527 |5.032976449684617 |18 |261 |2022-04-26 15:26:56|
|283127|Tom London |525 |2.8721716524875673|17 |203 |2022-04-26 15:26:56|
|356804|Bud Osborne |515 |2.0389507108727773|15 |149 |2022-04-26 15:26:56|
+------+------------+----------+------------------+------+---------+-------------------+
Creating a Table Materialization
In the previous example, our model was materialized as a view. While this might offer sufficient performance for some queries, more complex SELECTs or frequently executed queries may be better materialized as a table. This materialization is useful for models that will be queried by BI tools to ensure users have a faster experience. This effectively causes the query results to be stored as a new table, with the associated storage overheads - effectively, an INSERT TO SELECT is executed. Note that this table will be reconstructed each time i.e., it is not incremental. Large result sets may therefore result in long execution times - see dbt Limitations.
Modify the file
actors_summary.sqlsuch that thematerializedparameter is set totable. Notice howORDER BYis defined, and notice we use theMergeTreetable engine:{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='table') }}From the
imdbdirectory execute the commanddbt run. This execution may take a little longer to execute - around 10s on most machines.clickhouse-user@clickhouse:~/imdb$ dbt run
15:13:27 Running with dbt=1.1.0
15:13:27 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
15:13:27
15:13:28 Concurrency: 1 threads (target='dev')
15:13:28
15:13:28 1 of 1 START table model imdb_dbt.actor_summary................................. [RUN]
15:13:37 1 of 1 OK created table model imdb_dbt.actor_summary............................ [OK in 9.22s]
15:13:37
15:13:37 Finished running 1 table model in 10.20s.
15:13:37
15:13:37 Completed successfully
15:13:37
15:13:37 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1Confirm the creation of the table
imdb_dbt.actor_summary:SHOW CREATE TABLE imdb_dbt.actor_summary;You should the table with the appropriate data types:
+----------------------------------------
|statement
+----------------------------------------
|CREATE TABLE imdb_dbt.actor_summary
|(
|`id` UInt32,
|`first_name` String,
|`last_name` String,
|`num_movies` UInt64,
|`updated_at` DateTime
|)
|ENGINE = MergeTree
|ORDER BY (id, first_name, last_name)
|SETTINGS index_granularity = 8192
+----------------------------------------Confirm the results from this table are consistent with previous responses. Notice an appreciable improvement in the response time now that the model is a table:
SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 5;+------+------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+------------+----------+------------------+------+---------+-------------------+
|45332 |Mel Blanc |832 |6.175853582979779 |18 |84 |2022-04-26 15:26:55|
|621468|Bess Flowers|659 |5.57727638854796 |19 |293 |2022-04-26 15:26:57|
|372839|Lee Phelps |527 |5.032976449684617 |18 |261 |2022-04-26 15:26:56|
|283127|Tom London |525 |2.8721716524875673|17 |203 |2022-04-26 15:26:56|
|356804|Bud Osborne |515 |2.0389507108727773|15 |149 |2022-04-26 15:26:56|
+------+------------+----------+------------------+------+---------+-------------------+Feel free to issue other queries against this model. For example, which actors have the highest ranking movies with more than 5 appearances?
SELECT * FROM imdb_dbt.actor_summary WHERE num_movies > 5 ORDER BY avg_rank DESC LIMIT 10;
Creating an Incremental Materialization
The previous example created a table to materialize the model. This table will be reconstructed for each dbt execution. This may be infeasible and extremely costly for larger result sets or complex transformations. To address this challenge and reduce the build time, dbt offers Incremental materializations. This allows dbt to insert or update records into a table since the last execution, making it appropriate for event-style data. Under the hood a temporary table is created with all the updated records and then all the untouched records as well as the updated records are inserted into a new target table. This results in similar limitations for large result sets as for the table model.
To overcome these limitations for large sets, the plugin supports ‘inserts_only‘ mode, where all the updates are inserted into the target table without creating a temporary table (more about it below).
To illustrate this example, we will add the actor "Clicky McClickHouse", who will appear in an incredible 910 movies - ensuring he has appeared in more films than even Mel Blanc.
First, we modify our model to be of type incremental. This addition requires:
- unique_key - To ensure the plugin can uniquely identify rows, we must provide a unique_key - in this case, the
idfield from our query will suffice. This ensures we will have no row duplicates in our materialized table. For more details on uniqueness constraints, see here. - Incremental filter - We also need to tell dbt how it should identify which rows have changed on an incremental run. This is achieved by providing a delta expression. Typically this involves a timestamp for event data; hence our updated_at timestamp field. This column, which defaults to the value of now() when rows are inserted, allows new roles to be identified. Additionally, we need to identify the alternative case where new actors are added. Using the {{this}} variable, to denote the existing materialized table, this gives us the expression
where id > (select max(id) from {{ this }}) or updated_at > (select max(updated_at) from {{this}}). We embed this inside the{% if is_incremental() %}condition, ensuring it is only used on incremental runs and not when the table is first constructed. For more details on filtering rows for incremental models, see this discussion in the dbt docs.
Update the file
actor_summary.sqlas follows:{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='incremental', unique_key='id') }}
with actor_summary as (
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as genres,
uniqExact(director_name) as directors,
max(created_at) as updated_at
FROM (
SELECT {{ source('imdb', 'actors') }}.id as id,
concat({{ source('imdb', 'actors') }}.first_name, ' ', {{ source('imdb', 'actors') }}.last_name) as actor_name,
{{ source('imdb', 'movies') }}.id as movie_id,
{{ source('imdb', 'movies') }}.rank as rank,
genre,
concat({{ source('imdb', 'directors') }}.first_name, ' ', {{ source('imdb', 'directors') }}.last_name) as director_name,
created_at
FROM {{ source('imdb', 'actors') }}
JOIN {{ source('imdb', 'roles') }} ON {{ source('imdb', 'roles') }}.actor_id = {{ source('imdb', 'actors') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movies') }} ON {{ source('imdb', 'movies') }}.id = {{ source('imdb', 'roles') }}.movie_id
LEFT OUTER JOIN {{ source('imdb', 'genres') }} ON {{ source('imdb', 'genres') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movie_directors') }} ON {{ source('imdb', 'movie_directors') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'directors') }} ON {{ source('imdb', 'directors') }}.id = {{ source('imdb', 'movie_directors') }}.director_id
)
GROUP BY id
)
select *
from actor_summary
{% if is_incremental() %}
-- this filter will only be applied on an incremental run
where id > (select max(id) from {{ this }}) or updated_at > (select max(updated_at) from {{this}})
{% endif %}Note that our model will only respond to updates and additions to the
rolesandactorstables. To respond to all tables, users would be encouraged to split this model into multiple sub-models - each with their own incremental criteria. These models can in turn be referenced and connected. For further details on cross-referencing models see here.- unique_key - To ensure the plugin can uniquely identify rows, we must provide a unique_key - in this case, the
Execute a
dbt runand confirm the results of the resulting table:clickhouse-user@clickhouse:~/imdb$ dbt run
15:33:34 Running with dbt=1.1.0
15:33:34 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
15:33:34
15:33:35 Concurrency: 1 threads (target='dev')
15:33:35
15:33:35 1 of 1 START incremental model imdb_dbt.actor_summary........................... [RUN]
15:33:41 1 of 1 OK created incremental model imdb_dbt.actor_summary...................... [OK in 6.33s]
15:33:41
15:33:41 Finished running 1 incremental model in 7.30s.
15:33:41
15:33:41 Completed successfully
15:33:41
15:33:41 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 5;+------+------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+------------+----------+------------------+------+---------+-------------------+
|45332 |Mel Blanc |832 |6.175853582979779 |18 |84 |2022-04-26 15:26:55|
|621468|Bess Flowers|659 |5.57727638854796 |19 |293 |2022-04-26 15:26:57|
|372839|Lee Phelps |527 |5.032976449684617 |18 |261 |2022-04-26 15:26:56|
|283127|Tom London |525 |2.8721716524875673|17 |203 |2022-04-26 15:26:56|
|356804|Bud Osborne |515 |2.0389507108727773|15 |149 |2022-04-26 15:26:56|
+------+------------+----------+------------------+------+---------+-------------------+We will now add data to our model to illustrate an incremental update. Add our actor "Clicky McClickHouse" to the
actorstable:INSERT INTO imdb.actors VALUES (845466, 'Clicky', 'McClickHouse', 'M');Let's have Clicky star in 910 random movies:
INSERT INTO imdb.roles
SELECT now() as created_at, 845466 as actor_id, id as movie_id, 'Himself' as role
FROM imdb.movies
LIMIT 910 OFFSET 10000;Confirm he is indeed now the actor with the most appearances by querying the underlying source table and bypassing any dbt models:
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as unique_genres,
uniqExact(director_name) as uniq_directors,
max(created_at) as updated_at
FROM (
SELECT imdb.actors.id as id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) as actor_name,
imdb.movies.id as movie_id,
imdb.movies.rank as rank,
genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) as director_name,
created_at
FROM imdb.actors
JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT OUTER JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT OUTER JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
ORDER BY num_movies DESC
LIMIT 2;+------+-------------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+-------------------+----------+------------------+------+---------+-------------------+
|845466|Clicky McClickHouse|910 |1.4687938697032283|21 |662 |2022-04-26 16:20:36|
|45332 |Mel Blanc |909 |5.7884792542982515|19 |148 |2022-04-26 16:17:42|
+------+-------------------+----------+------------------+------+---------+-------------------+Execute a
dbt runand confirm our model has been updated and matches the above results:clickhouse-user@clickhouse:~/imdb$ dbt run
16:12:16 Running with dbt=1.1.0
16:12:16 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
16:12:16
16:12:17 Concurrency: 1 threads (target='dev')
16:12:17
16:12:17 1 of 1 START incremental model imdb_dbt.actor_summary........................... [RUN]
16:12:24 1 of 1 OK created incremental model imdb_dbt.actor_summary...................... [OK in 6.82s]
16:12:24
16:12:24 Finished running 1 incremental model in 7.79s.
16:12:24
16:12:24 Completed successfully
16:12:24
16:12:24 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 2;+------+-------------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+-------------------+----------+------------------+------+---------+-------------------+
|845466|Clicky McClickHouse|910 |1.4687938697032283|21 |662 |2022-04-26 16:20:36|
|45332 |Mel Blanc |909 |5.7884792542982515|19 |148 |2022-04-26 16:17:42|
+------+-------------------+----------+------------------+------+---------+-------------------+
Internals
We can identify the statements executed to achieve the above incremental update by querying ClickHouse’s query log.
SELECT event_time, query FROM system.query_log WHERE type='QueryStart' AND query LIKE '%dbt%'
AND event_time > subtractMinutes(now(), 15) ORDER BY event_time LIMIT 100;
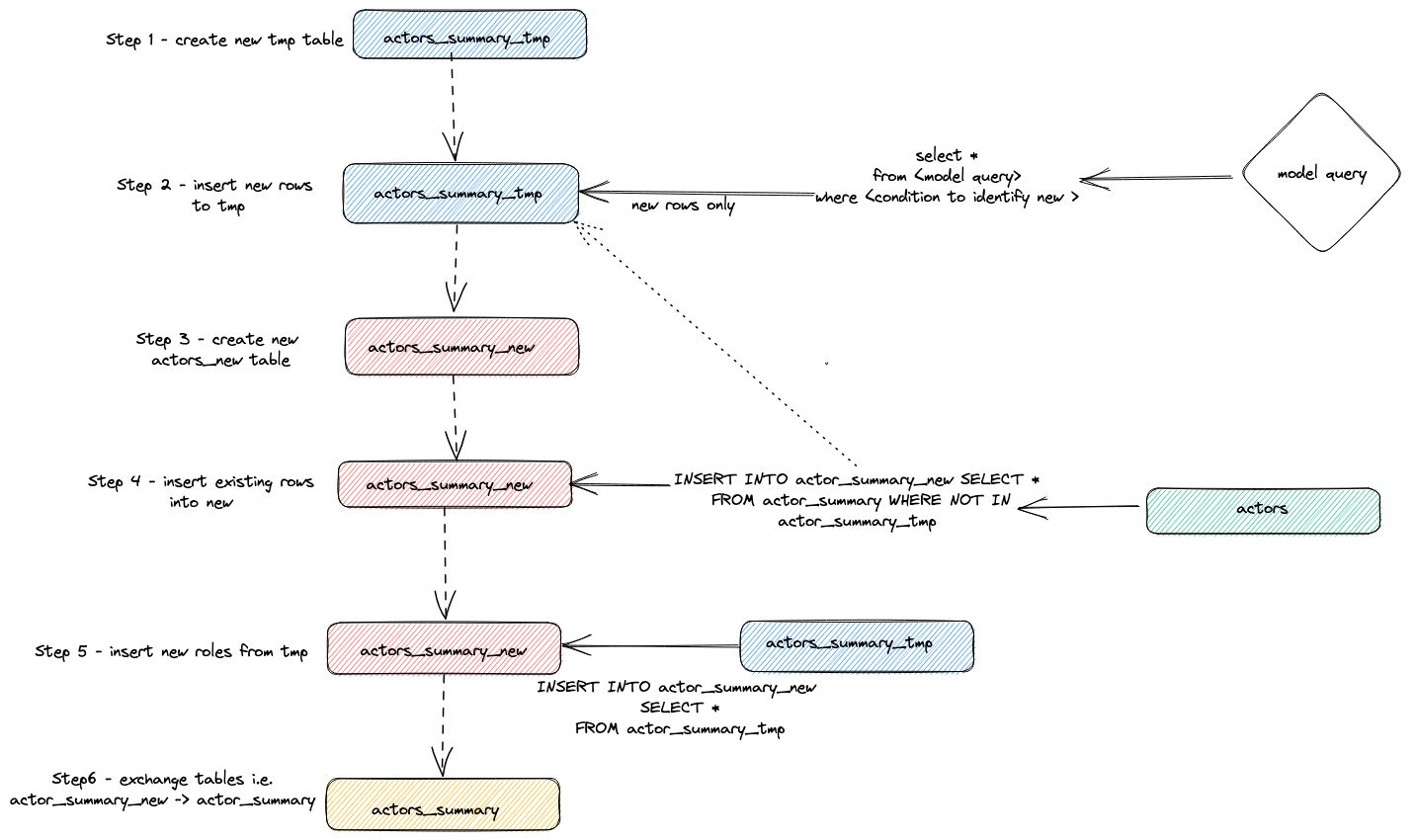
Adjust the above query to the period of execution. We leave result inspection to the user but highlight the general strategy used by the plugin to perform incremental updates:
- The plugin creates a temporary table
actor_sumary__dbt_tmp. Rows that have changed are streamed into this table. - A new table,
actor_summary_new,is created. The rows from the old table are, in turn, streamed from the old to new, with a check to make sure row ids do not exist in the temporary table. This effectively handles updates and duplicates. - The results from the temporary table are streamed into the new
actor_summarytable: - Finally, the new table is exchanged atomically with the old version via an
EXCHANGE TABLESstatement. The old and temporary tables are in turn dropped.
This is visualized below:
This strategy may encounter challenges on very large models. For further details see Limitations.
Append Strategy (inserts-only mode)
To overcome the limitations of large datasets in incremental models, the plugin uses the dbt configuration parameter incremental_strategy. This can be set to the value append. When set, updated rows are inserted directly into the target table (a.k.a imdb_dbt.actor_summary) and no temporary table is created.
Note: Append only mode requires your data to be immutable or for duplicates to be acceptable. If you want an incremental table model that supports altered rows don’t use this mode!
To illustrate this mode, we will add another new actor and re-execute dbt run with incremental_strategy='append'.
Configure append only mode in actor_summary.sql:
{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='incremental', unique_key='id', incremental_strategy='append') }}Let’s add another famous actor - Danny DeBito
INSERT INTO imdb.actors VALUES (845467, 'Danny', 'DeBito', 'M');Let's star Danny in 920 random movies.
INSERT INTO imdb.roles
SELECT now() as created_at, 845467 as actor_id, id as movie_id, 'Himself' as role
FROM imdb.movies
LIMIT 920 OFFSET 10000;Execute a dbt run and confirm that Danny was added to the actor-summary table
clickhouse-user@clickhouse:~/imdb$ dbt run
16:12:16 Running with dbt=1.1.0
16:12:16 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 186 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
16:12:16
16:12:17 Concurrency: 1 threads (target='dev')
16:12:17
16:12:17 1 of 1 START incremental model imdb_dbt.actor_summary........................... [RUN]
16:12:24 1 of 1 OK created incremental model imdb_dbt.actor_summary...................... [OK in 0.17s]
16:12:24
16:12:24 Finished running 1 incremental model in 0.19s.
16:12:24
16:12:24 Completed successfully
16:12:24
16:12:24 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 3;+------+-------------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+-------------------+----------+------------------+------+---------+-------------------+
|845467|Danny DeBito |920 |1.4768987303293204|21 |670 |2022-04-26 16:22:06|
|845466|Clicky McClickHouse|910 |1.4687938697032283|21 |662 |2022-04-26 16:20:36|
|45332 |Mel Blanc |909 |5.7884792542982515|19 |148 |2022-04-26 16:17:42|
+------+-------------------+----------+------------------+------+---------+-------------------+
Note how much faster that incremental was compared to the insertion of Clicky.
Checking again the query_log table reveals the differences between the 2 incremental runs:
insert into imdb_dbt.actor_summary ("id", "name", "num_movies", "avg_rank", "genres", "directors", "updated_at")
with actor_summary as (
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as genres,
uniqExact(director_name) as directors,
max(created_at) as updated_at
FROM (
SELECT imdb.actors.id as id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) as actor_name,
imdb.movies.id as movie_id,
imdb.movies.rank as rank,
genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) as director_name,
created_at
FROM imdb.actors
JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT OUTER JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT OUTER JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
)
select *
from actor_summary
-- this filter will only be applied on an incremental run
where id > (select max(id) from imdb_dbt.actor_summary) or updated_at > (select max(updated_at) from imdb_dbt.actor_summary)
In this run, only the new rows are added straight to imdb_dbt.actor_summary table and there is no table creation involved.
Delete+Insert mode (Experimental)
Historically ClickHouse has had only limited support for updates and deletes, in the form of asynchronous Mutations. These can be extremely IO-intensive and should generally be avoided.
ClickHouse 22.8 introduced Lightweight deletes. These are currently experimental but offer a more performant means of deleting data.
This mode can be configured for a model via the incremental_strategy parameter i.e.
{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='incremental', unique_key='id', incremental_strategy='delete+insert') }}
This strategy operates directly on the target model's table, so if there is an issue during the operation, the data in the incremental model is likely to be in an invalid state - there is no atomic update.
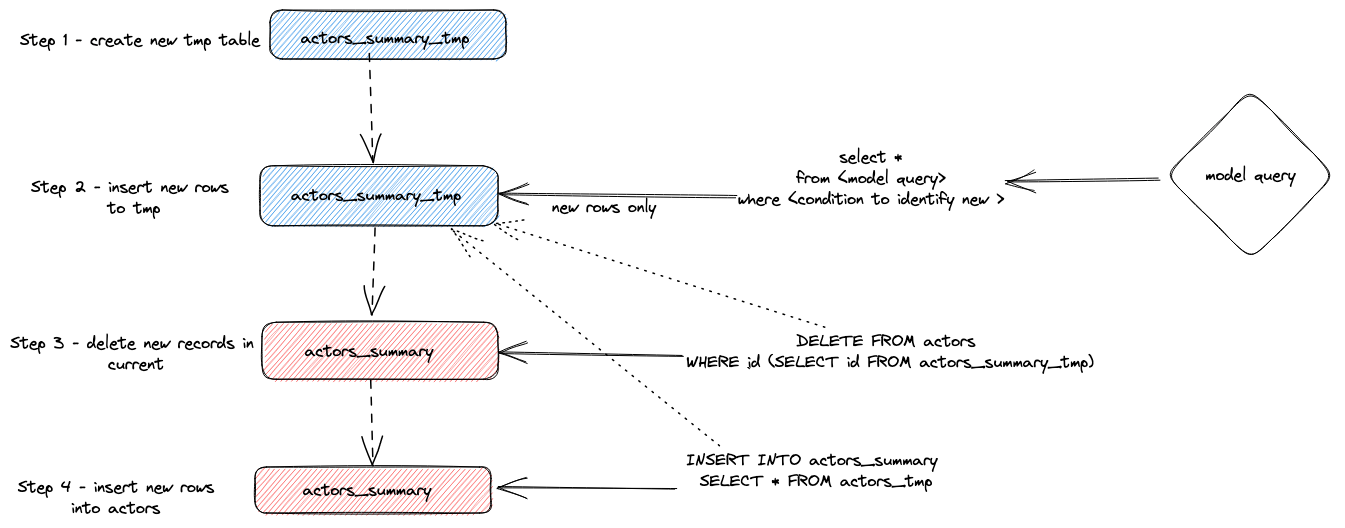
In summary, this approach:
- The plugin creates a temporary table
actor_sumary__dbt_tmp. Rows that have changed are streamed into this table. - A
DELETEis issued against the currentactor_summarytable. Rows are deleted by id fromactor_sumary__dbt_tmp - The rows from
actor_sumary__dbt_tmpare inserted intoactor_summaryusing anINSERT INTO actor_summary SELECT * FROM actor_sumary__dbt_tmp.
This process is shown below:
insert_overwrite mode (Experimental)
Performs the following steps:
- Create a staging (temporary) table with the same structure as the incremental model relation: CREATE TABLE {staging} AS {target}.
- Insert only new records (produced by SELECT) into the staging table.
- Replace only new partitions (present in the staging table) into the target table.
This approach has the following advantages:
- It is faster than the default strategy because it doesn't copy the entire table.
- It is safer than other strategies because it doesn't modify the original table until the INSERT operation completes successfully: in case of intermediate failure, the original table is not modified.
- It implements "partitions immutability" data engineering best practice. Which simplifies incremental and parallel data processing, rollbacks, etc.
The insert_overwrite feature wasn't tested yet on a multi node setup.
For detailed information on the implementation of this feature, please review the PR that introduced it.
Creating a Snapshot
dbt snapshots allow a record to be made of changes to a mutable model over time. This in turn allows point-in-time queries on models, where analysts can “look back in time” at the previous state of a model. This is achieved using type-2 Slowly Changing Dimensions where from and to date columns record when a row was valid. This functionality is supported by the ClickHouse plugin and is demonstrated below.
This example assumes you have completed Creating an Incremental Table Model. Make sure your actor_summary.sql doesn't set inserts_only=True. Your models/actor_summary.sql should look like this:
{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='incremental', unique_key='id') }}
with actor_summary as (
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as genres,
uniqExact(director_name) as directors,
max(created_at) as updated_at
FROM (
SELECT {{ source('imdb', 'actors') }}.id as id,
concat({{ source('imdb', 'actors') }}.first_name, ' ', {{ source('imdb', 'actors') }}.last_name) as actor_name,
{{ source('imdb', 'movies') }}.id as movie_id,
{{ source('imdb', 'movies') }}.rank as rank,
genre,
concat({{ source('imdb', 'directors') }}.first_name, ' ', {{ source('imdb', 'directors') }}.last_name) as director_name,
created_at
FROM {{ source('imdb', 'actors') }}
JOIN {{ source('imdb', 'roles') }} ON {{ source('imdb', 'roles') }}.actor_id = {{ source('imdb', 'actors') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movies') }} ON {{ source('imdb', 'movies') }}.id = {{ source('imdb', 'roles') }}.movie_id
LEFT OUTER JOIN {{ source('imdb', 'genres') }} ON {{ source('imdb', 'genres') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movie_directors') }} ON {{ source('imdb', 'movie_directors') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'directors') }} ON {{ source('imdb', 'directors') }}.id = {{ source('imdb', 'movie_directors') }}.director_id
)
GROUP BY id
)
select *
from actor_summary
{% if is_incremental() %}
-- this filter will only be applied on an incremental run
where id > (select max(id) from {{ this }}) or updated_at > (select max(updated_at) from {{this}})
{% endif %}
Create a file
actor_summaryin the snapshots directory.touch snapshots/actor_summary.sqlUpdate the contents of the actor_summary.sql file with the following content:
{% snapshot actor_summary_snapshot %}
{{
config(
target_schema='snapshots',
unique_key='id',
strategy='timestamp',
updated_at='updated_at',
)
}}
select * from {{ref('actor_summary')}}
{% endsnapshot %}
A few observations regarding this content:
- The select query defines the results you wish to snapshot over time. The function ref is used to reference our previously created actor_summary model.
- We require a timestamp column to indicate record changes. Our updated_at column (see Creating an Incremental Table Model) can be used here. The parameter strategy indicates our use of a timestamp to denote updates, with the parameter updated_at specifying the column to use. If this is not present in your model you can alternatively use the check strategy. This is significantly more inefficient and requires the user to specify a list of columns to compare. dbt compares the current and historical values of these columns, recording any changes (or doing nothing if identical).
Run the command
dbt snapshot.clickhouse-user@clickhouse:~/imdb$ dbt snapshot
13:26:23 Running with dbt=1.1.0
13:26:23 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 3 sources, 0 exposures, 0 metrics
13:26:23
13:26:25 Concurrency: 1 threads (target='dev')
13:26:25
13:26:25 1 of 1 START snapshot snapshots.actor_summary_snapshot...................... [RUN]
13:26:25 1 of 1 OK snapshotted snapshots.actor_summary_snapshot...................... [OK in 0.79s]
13:26:25
13:26:25 Finished running 1 snapshot in 2.11s.
13:26:25
13:26:25 Completed successfully
13:26:25
13:26:25 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
Note how a table actor_summary_snapshot has been created in the snapshots db (determined by the target_schema parameter).
Sampling this data you will see how dbt has included the columns dbt_valid_from and dbt_valid_to. The latter has values set to null. Subsequent runs will update this.
SELECT id, name, num_movies, dbt_valid_from, dbt_valid_to FROM snapshots.actor_summary_snapshot ORDER BY num_movies DESC LIMIT 5;+------+----------+------------+----------+-------------------+------------+
|id |first_name|last_name |num_movies|dbt_valid_from |dbt_valid_to|
+------+----------+------------+----------+-------------------+------------+
|845467|Danny |DeBito |920 |2022-05-25 19:33:32|NULL |
|845466|Clicky |McClickHouse|910 |2022-05-25 19:32:34|NULL |
|45332 |Mel |Blanc |909 |2022-05-25 19:31:47|NULL |
|621468|Bess |Flowers |672 |2022-05-25 19:31:47|NULL |
|283127|Tom |London |549 |2022-05-25 19:31:47|NULL |
+------+----------+------------+----------+-------------------+------------+Make our favorite actor Clicky McClickHouse appear in another 10 films.
INSERT INTO imdb.roles
SELECT now() as created_at, 845466 as actor_id, rand(number) % 412320 as movie_id, 'Himself' as role
FROM system.numbers
LIMIT 10;Re-run the dbt run command from the imdb directory. This will update the incremental model. Once this is complete, run the dbt snapshot to capture the changes.
clickhouse-user@clickhouse:~/imdb$ dbt run
13:46:14 Running with dbt=1.1.0
13:46:14 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 3 sources, 0 exposures, 0 metrics
13:46:14
13:46:15 Concurrency: 1 threads (target='dev')
13:46:15
13:46:15 1 of 1 START incremental model imdb_dbt.actor_summary....................... [RUN]
13:46:18 1 of 1 OK created incremental model imdb_dbt.actor_summary.................. [OK in 2.76s]
13:46:18
13:46:18 Finished running 1 incremental model in 3.73s.
13:46:18
13:46:18 Completed successfully
13:46:18
13:46:18 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
clickhouse-user@clickhouse:~/imdb$ dbt snapshot
13:46:26 Running with dbt=1.1.0
13:46:26 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 3 sources, 0 exposures, 0 metrics
13:46:26
13:46:27 Concurrency: 1 threads (target='dev')
13:46:27
13:46:27 1 of 1 START snapshot snapshots.actor_summary_snapshot...................... [RUN]
13:46:31 1 of 1 OK snapshotted snapshots.actor_summary_snapshot...................... [OK in 4.05s]
13:46:31
13:46:31 Finished running 1 snapshot in 5.02s.
13:46:31
13:46:31 Completed successfully
13:46:31
13:46:31 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1If we now query our snapshot, notice we have 2 rows for Clicky McClickHouse. Our previous entry now has a dbt_valid_to value. Our new value is recorded with the same value in the dbt_valid_from column, and a dbt_valid_to value of null. If we did have new rows, these would also be appended to the snapshot.
SELECT id, name, num_movies, dbt_valid_from, dbt_valid_to FROM snapshots.actor_summary_snapshot ORDER BY num_movies DESC LIMIT 5;+------+----------+------------+----------+-------------------+-------------------+
|id |first_name|last_name |num_movies|dbt_valid_from |dbt_valid_to |
+------+----------+------------+----------+-------------------+-------------------+
|845467|Danny |DeBito |920 |2022-05-25 19:33:32|NULL |
|845466|Clicky |McClickHouse|920 |2022-05-25 19:34:37|NULL |
|845466|Clicky |McClickHouse|910 |2022-05-25 19:32:34|2022-05-25 19:34:37|
|45332 |Mel |Blanc |909 |2022-05-25 19:31:47|NULL |
|621468|Bess |Flowers |672 |2022-05-25 19:31:47|NULL |
+------+----------+------------+----------+-------------------+-------------------+
For further details on dbt snapshots see here.
Using Seeds
dbt provides the ability to load data from CSV files. This capability is not suited to loading large exports of a database and is more designed for small files typically used for code tables and dictionaries, e.g. mapping country codes to country names. For a simple example, we generate and then upload a list of genre codes using the seed functionality.
We generate a list of genre codes from our existing dataset. From the dbt directory, use the
clickhouse-clientto create a fileseeds/genre_codes.csv:clickhouse-user@clickhouse:~/imdb$ clickhouse-client --password <password> --query
"SELECT genre, ucase(substring(genre, 1, 3)) as code FROM imdb.genres GROUP BY genre
LIMIT 100 FORMAT CSVWithNames" > seeds/genre_codes.csvExecute the
dbt seedcommand. This will create a new tablegenre_codesin our databaseimdb_dbt(as defined by our schema configuration) with the rows from our csv file.clickhouse-user@clickhouse:~/imdb$ dbt seed
17:03:23 Running with dbt=1.1.0
17:03:23 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 1 seed file, 6 sources, 0 exposures, 0 metrics
17:03:23
17:03:24 Concurrency: 1 threads (target='dev')
17:03:24
17:03:24 1 of 1 START seed file imdb_dbt.genre_codes..................................... [RUN]
17:03:24 1 of 1 OK loaded seed file imdb_dbt.genre_codes................................. [INSERT 21 in 0.65s]
17:03:24
17:03:24 Finished running 1 seed in 1.62s.
17:03:24
17:03:24 Completed successfully
17:03:24
17:03:24 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1Confirm these have been loaded:
SELECT * FROM imdb_dbt.genre_codes LIMIT 10;+-------+----+
|genre |code|
+-------+----+
|Drama |DRA |
|Romance|ROM |
|Short |SHO |
|Mystery|MYS |
|Adult |ADU |
|Family |FAM |
|Action |ACT |
|Sci-Fi |SCI |
|Horror |HOR |
|War |WAR |
+-------+----+=
Limitations
The current ClickHouse plugin for dbt has several limitations users should be aware of:
- The plugin currently materializes models as tables using an
INSERT TO SELECT. This effectively means data duplication. Very large datasets (PB) can result in extremely long run times, making some models unviable. Aim to minimize the number of rows returned by any query, utilizing GROUP BY where possible. Prefer models which summarize data over those which simply perform a transform whilst maintaining row counts of the source. - To use Distributed tables to represent a model, users must create the underlying replicated tables on each node manually. The Distributed table can, in turn, be created on top of these. The plugin does not manage cluster creation.
- When dbt creates a relation (table/view) in a database, it usually creates it as:
{{ database }}.{{ schema }}.{{ table/view id }}. ClickHouse has no notion of schemas. The plugin therefore uses{{schema}}.{{ table/view id }}, whereschemais the ClickHouse database.
Further Information
The previous guides only touch the surface of dbt functionality. Users are recommended to read the excellent dbt documentation.
Additional configuration for the plugin is described here.
Related Content
- Blog & Webinar: ClickHouse and dbt - A Gift from the Community